
AI agent development in 2026 has shifted from a research curiosity to a category that ships real revenue for real saas products. The shift happened faster than most categories: 2023 was the year of chat interfaces, 2024 was the year of tool-using agents, 2025 was the year of multi-agent systems, and 2026 is the year founders ship AI agent products that pass enterprise procurement and produce measurable ROI. Teams that learned AI agent development in 2024 are now shipping the production systems that competitors are racing to match.
This guide walks through the 7 critical steps in AI agent development that separate teams shipping working production agents from teams burning months on demos that never reach customers. Step 1 is defining the agent’s job-to-be-done so the scope stays disciplined. Step 2 is picking the right LLM provider for each task in the agent. Steps 3 through 7 build the five layers of the AI Agent Capability Stack: perception, reasoning, action, memory, and learning. Each step has concrete patterns, real numbers, and the specific decisions that determine whether the agent ships in 12 weeks or never.
Five takeaways before reading on: AI agent development is meaningfully different from chatbot development; the Capability Stack framework forces structured thinking instead of “let’s prompt our way out”; model selection is a per-task decision, not a per-product decision; the action layer (tool use) is where most agents fail; and the memory layer determines whether the agent retains users or churns them.
What AI Agent Development Actually Means in 2026
AI agent development is the engineering practice of building software systems that perceive context, reason about goals, take actions through tools, remember past interactions, and improve over time. The five-property definition matters because it separates true AI agents from chatbots, RPA bots, and prompt-engineered LLM wrappers that pose as agents.
A chatbot answers messages. An AI agent pursues a goal. The distinction matters at architecture: chatbots are stateless or session-stateful conversation engines; AI agents are stateful goal-pursuing systems with autonomy over which actions to take in what order. A user asks a chatbot “what is my balance”; the chatbot returns the balance. A user asks an AI agent “reconcile this month’s expenses and flag anything unusual”; the AI agent pulls the data, categorizes expenses, identifies anomalies, generates a report, and (with permission) emails it to the user. The same LLM can power both, but the engineering work to build the agent is meaningfully larger.
Three forces have shaped AI agent development since 2023. First, function calling and tool use APIs matured (OpenAI function calling 2023, Anthropic tool use 2024, MCP standardization 2024 to 2025). Second, vector databases became commodity infrastructure (pgvector, Pinecone, Weaviate all production-ready). Third, agent frameworks emerged (LangGraph, AutoGen, CrewAI) to handle the orchestration patterns that teams previously built from scratch.
The dominant 2026 default for AI agent development: a multi-tool agent powered by Claude or GPT-5, orchestrated through LangGraph or a custom state machine, retrieving from a pgvector or Pinecone vector store, persisting memory across sessions, and exposed through a saas product UI. This is the pattern most fixed-price MVP agent builds assume.
For the comparison question that many founders need to answer before committing to AI agent development, see AI agent vs chatbot.
The 7-Step AI Agent Development Roadmap
The AI agent development roadmap organizes work into 7 sequential steps. Each step produces a specific deliverable that gates the next step. Skipping or rushing any one step is the single most common cause of agent projects that ship demos but never ship production.
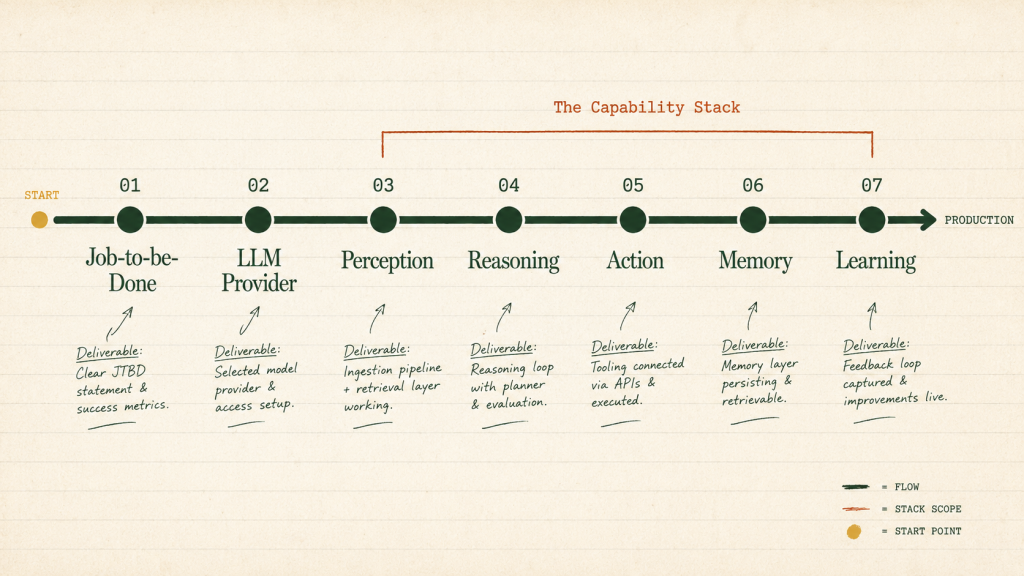
The 7 steps:
- Define the agent’s job-to-be-done. Scope, success metrics, user journey. Without this, the agent’s goals drift and the team builds 3 features that should have been 1.
- Pick the right LLM provider per task. Premium model for primary user surfaces, cheap model for background tasks, open-source where data residency demands it.
- Build the perception layer. Retrieval (RAG), context gathering, input parsing. The agent cannot reason about data it cannot see.
- Build the reasoning layer. Planning, decision-making, reflection. The cognitive core of the agent.
- Build the action layer. Tool use, API calls, MCP integration. Where most agents fail in production.
- Build the memory layer. Short-term working memory, long-term knowledge, episodic recall. Determines retention.
- Build the learning layer. Evaluation, feedback loops, improvement over time. What separates v1 agents from agents that compound value.
The roadmap is sequential but not rigid. Teams often iterate within steps (refine the perception layer based on what the reasoning layer reveals) and revisit earlier steps when later steps surface gaps. The discipline is treating each step as a deliverable with a measurable outcome, not as a phase that blurs into the next.
Each step in AI agent development carries a specific failure mode. Step 1 fails when scope is vague. Step 2 fails when teams pick a single model for every task. Step 3 fails when retrieval quality is unmeasured. Step 4 fails when the agent has no reflection mechanism. Step 5 fails when tool errors are unhandled. Step 6 fails when memory schemas are afterthoughts. Step 7 fails when there is no evaluation framework. Knowing the failure mode in advance is what prevents it.
Before You Start AI Agent Development: The Founder Readiness Check
Many AI agent development projects fail not because of execution but because the founder was not the right person to start one. Four readiness pillars separate teams that ship from teams that burn capital.
Use-case clarity. The team can name the specific user, the specific workflow being automated, and the specific value delivered. Vague use cases (“AI for productivity”) fail at scope definition in Step 1. Concrete use cases (“AI agent that drafts sales follow-up emails based on CRM history for B2B SDRs”) survive scoping.
LLM cost tolerance. AI agent development has real ongoing costs (inference, vector storage, infrastructure) that scale with usage. Founders who have not done the math on token costs per active user often discover at month 3 that the agent costs $40 per user per month to operate while charging $29 per month. Pricing tier design depends on knowing this number before the build, not after.
Engineering or partner capacity. AI agent development requires senior engineering judgment. The pattern of “let’s prompt-engineer our way out of this” produces brittle systems that fall over the first time real users push edge cases. Teams without senior AI engineering capacity should engage a specialized agency rather than learn on their first build.
Iteration discipline. AI agents improve through measured iteration: evaluate against test cases, identify failure modes, adjust prompts or architecture, re-evaluate. Teams that ship and walk away end up with agents that degrade as the underlying model API evolves. Plan for ongoing iteration as a permanent operational cost, not a one-time post-launch sprint.
Founders who score weak on two or more pillars should either build a different category (chatbot, simple LLM feature) or partner with an agency that brings the missing capability. The cost of AI agent development without these foundations is higher than founders typically expect.
AI Agent Development Step 1: Define the Agent’s Job-to-be-Done
Step 1 of AI agent development is the most under-invested step and the most predictive of project success. The team defines the agent’s specific job-to-be-done in language tight enough that the entire team can recite it.
The right job-to-be-done statement names four things: the user (role, segment), the trigger (when does the agent get invoked), the action sequence (what the agent does), and the success metric (how completion is measured).
Worked example. Bad job-to-be-done: “An AI agent that helps SaaS users with their work.”
Good job-to-be-done: “When a customer support agent at a B2B SaaS company under 200 employees opens a new ticket, our AI agent reads the ticket, retrieves similar past tickets and their resolutions from the knowledge base, drafts a response with citations, and presents it for review within 8 seconds. Success is measured by support agent time-to-first-response reduced by 60 percent and first-response acceptance rate above 70 percent.”
The good version produces an unambiguous build target. The bad version produces three months of scope drift while the team argues about what “help users” means.
Three patterns to avoid in AI agent development Step 1. First, treating the agent as a feature rather than a workflow. Features are passive surfaces; agents pursue goals. Second, naming generic users instead of specific roles. “Customers” is not a user; “B2B SDR at a 50 to 200 person company” is. Third, omitting success metrics. Without metrics, the agent has no way to know whether it succeeded, and the team has no way to evaluate iterations.
The deliverable for Step 1 is a one-page document the entire team agrees on: user, trigger, action sequence, success metric, and explicit non-goals (what the agent does not do). The document is short on purpose; long documents hide scope creep.
AI Agent Development Step 2: Pick the Right LLM Provider per Task
Step 2 of AI agent development is the model selection decision, and the right answer is rarely a single model. Production agents in 2026 typically use 2 to 4 different models routed by task.
Premium models for primary user surfaces. Claude (Sonnet, Opus) and GPT-5 lead on reasoning quality, structured-output reliability, and the long-context windows agents need for complex tasks. Use premium models for the user-facing surfaces where reasoning quality matters and latency budgets allow 1 to 5 seconds.
Cheap models for background and batch tasks. Haiku, GPT-5-mini, Gemini Flash handle classification, summarization, simple extraction, and batch processing at 1/10 to 1/30 the cost of premium models. Background workflows that process documents, classify intent, or perform first-pass triage should use cheap models. The cost difference compounds at scale: a B2B agent processing 10,000 background tasks per day saves $300 to $1,500 per day by routing those tasks to cheap models.
Open-source models for data residency and specialized fine-tuning. Llama (Meta), Mistral, Qwen run on self-hosted infrastructure when data residency requirements (EU, healthcare, financial services) prohibit sending data to commercial APIs. Open-source models also support fine-tuning for vertical-specific tasks where a smaller fine-tuned model outperforms a larger general model. The trade-off is operational complexity: self-hosting models requires GPU infrastructure (A100, H100), inference framework setup (vLLM, TGI), and ongoing maintenance.
Specialized models for specific modalities. Vision tasks use multimodal models (Claude with images, GPT-5 vision, Gemini). Voice tasks use specialized providers (ElevenLabs, OpenAI Realtime API, Anthropic voice when available). Code generation uses code-specialized models (Claude, GPT-5, DeepSeek-Coder). Multi-modal agents in 2026 routinely combine 3 to 5 different providers based on task type.
The routing pattern that works in production: a small classifier model (cheap, fast) at the top of the agent decides which downstream model handles each task. This pattern reduces total inference cost by 40 to 70 percent versus using premium models for every step.
The canonical references for the major model providers are the Anthropic Claude API documentation and the OpenAI API documentation.
The AI Agent Capability Stack: A 5-Layer AI Agent Development Framework
The AI Agent Capability Stack is the framework this guide is built around. Every production AI agent implements five layers (perception, reasoning, action, memory, learning). Teams that build all five ship working agents. Teams that skip layers ship demos that fall over in production.
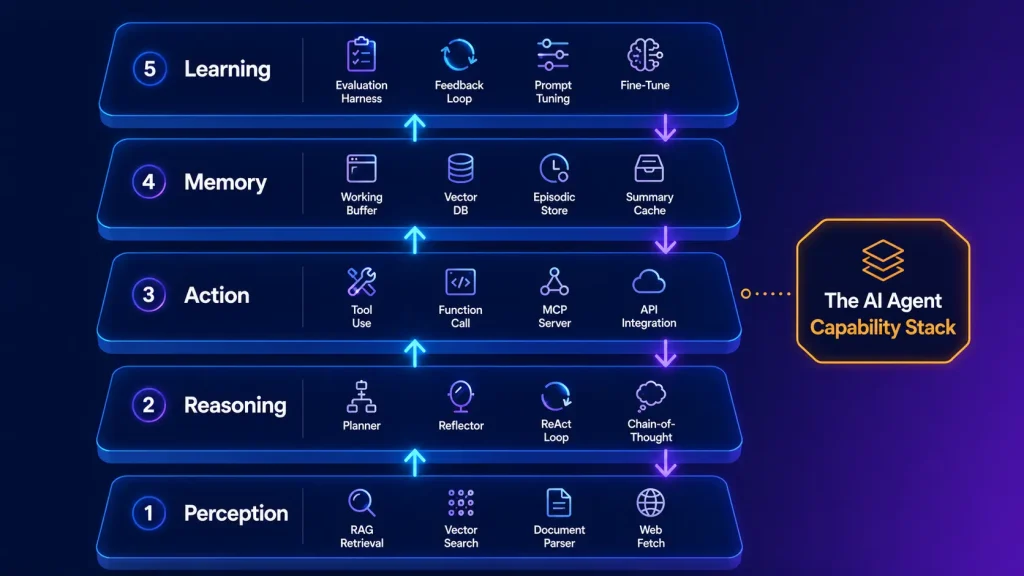
Layer 1: Perception. How the agent understands its environment. Retrieval-augmented generation (RAG) pulls relevant context from vector stores. Document parsers extract structured data from unstructured input. Web fetching grabs real-time information. Without strong perception, the agent reasons about incomplete data and produces wrong answers confidently.
Layer 2: Reasoning. How the agent thinks. Chain-of-thought prompting structures the model’s internal reasoning. ReAct (Reasoning + Acting) interleaves thinking and tool use. Reflection lets the agent critique its own outputs. Planning decomposes complex goals into ordered steps. The reasoning layer is what makes an agent different from a function call.
Layer 3: Action. How the agent affects the world. Function calling and tool use let the agent invoke APIs, databases, third-party services. The Model Context Protocol (MCP) standardizes tool definitions across agent implementations. The action layer is where most agent projects fail in production because edge cases (timeouts, errors, partial results, permission issues) compound rapidly.
Layer 4: Memory. What the agent remembers. Working memory holds the current conversation context. Short-term memory caches recent sessions. Long-term memory stores user preferences, history, and learned patterns in vector databases. Episodic memory replays specific past interactions. Strong memory is what turns one-shot demos into agents users return to daily.
Layer 5: Learning. How the agent improves. Evaluation harnesses test the agent against curated test cases. Feedback loops capture user corrections. Prompt tuning iterates on system prompts based on failure data. Fine-tuning specializes the model for vertical-specific tasks. Without the learning layer, the agent degrades as the underlying model API evolves and the user’s needs shift.
Each layer has its own engineering work and its own production failure modes. The full framework lives at AI agent architecture, where the architectural patterns for each layer are documented in production-grade depth.
AI Agent Development Step 3: Build the Perception Layer
Step 3 of AI agent development is the perception layer. The agent needs to gather context relevant to the user’s task before reasoning about it. Three sub-systems make up the perception layer.
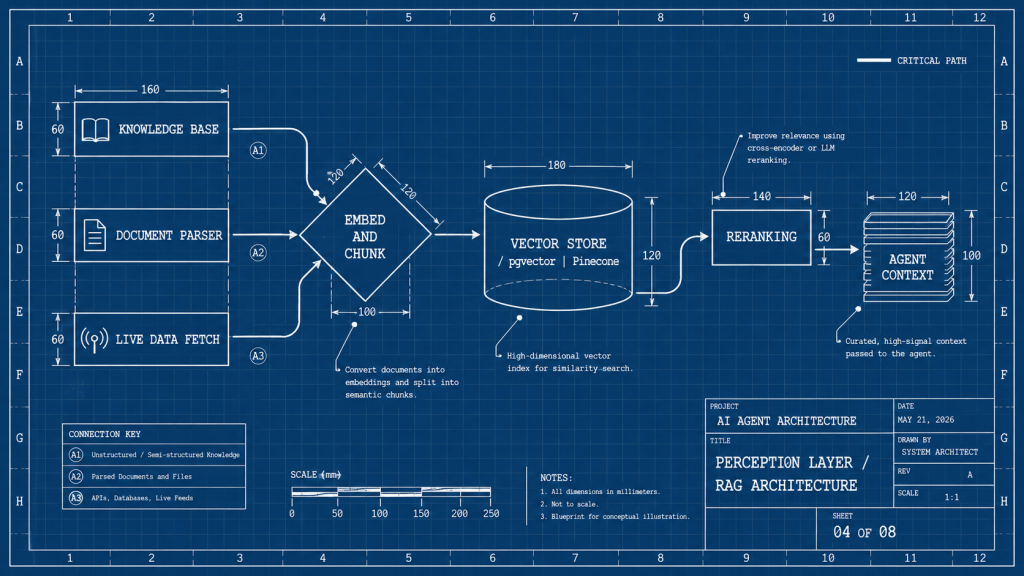
Retrieval-Augmented Generation (RAG). The dominant 2026 pattern. User data, knowledge base articles, past conversations, and reference documents get chunked, embedded into vectors, and stored in a vector database. At query time, the agent embeds the user’s input, performs semantic similarity search against the vector store, and retrieves the top-k most relevant chunks to include as context for reasoning.
The architectural decisions in RAG: chunk size (typically 300 to 1,000 tokens), chunk overlap (10 to 20 percent), embedding model (OpenAI text-embedding-3, Voyage, Cohere, open-source alternatives like BGE), vector database (pgvector for tight integration with Postgres, Pinecone for managed scale, Weaviate for hybrid search), and retrieval strategy (semantic only, hybrid with keyword, reranking with a second-pass model). Each decision has measurable impact on retrieval quality; teams that do not measure end up with agents that retrieve irrelevant context confidently.
Document parsing and extraction. Many AI agent development projects need to extract structured data from unstructured input: PDFs, scanned documents, emails, web pages, CSVs. Document parsing tools (Unstructured, LlamaParse, OCR services for scanned content) convert unstructured input into structured chunks the agent can reason about. Skipping this work produces agents that fail on real-world inputs.
Live data fetching. Some agent tasks require real-time data: current pricing, latest inventory, today’s weather, recent news. The perception layer includes API clients and (sometimes) browser-use capabilities for fetching live data. Caching strategies prevent over-fetching; cache invalidation patterns prevent stale data.
The deliverable for Step 3 is a working retrieval system that the team has measured: precision at 5 (how many of the top 5 retrieved chunks are actually relevant), recall at 10 (how many relevant chunks appear in top 10), and end-to-end retrieval latency (target under 200ms for self-serve, under 500ms for sales-led). Teams that ship perception without measurement discover at month 3 that 40 percent of retrieved chunks are noise.
AI Agent Development Step 4: Build the Reasoning Layer
Step 4 of AI agent development is the reasoning layer. The agent uses the LLM to think through the user’s goal, decide what actions to take, and reflect on outcomes. Five patterns dominate production reasoning in 2026.
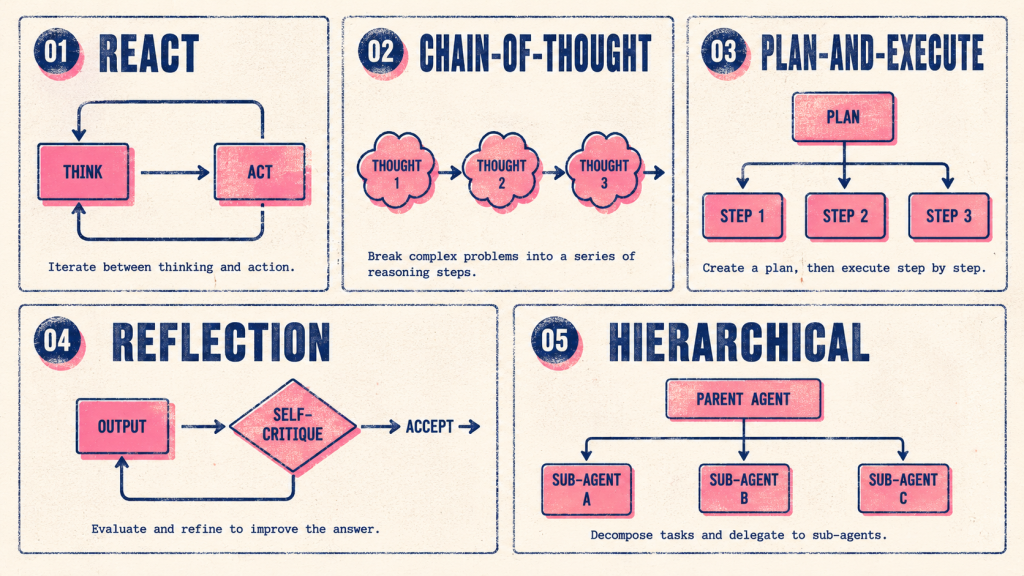
ReAct (Reasoning + Acting). The agent alternates between reasoning steps (“I need to find the user’s last invoice”) and action steps (calling a tool to fetch the invoice). The reasoning trace is visible to the agent and (often) to developers for debugging. ReAct is the default reasoning pattern for tool-using agents because it produces interpretable decision trails.
Chain-of-Thought (CoT). The agent explicitly writes out its reasoning before producing a final answer. CoT improves accuracy on complex reasoning tasks (math, logic, multi-step decisions) at the cost of additional tokens. Most production agents use CoT prompting on premium models for any task that involves more than one step of reasoning.
Plan-and-Execute. The agent generates a multi-step plan upfront, then executes each step (with adjustments based on intermediate results). Plan-and-Execute is the right pattern for complex tasks with predictable structure (research workflows, multi-document analysis). It is the wrong pattern for tasks where the next step truly depends on the previous step’s outcome; ReAct handles that pattern better.
Reflection. The agent critiques its own output before returning it. Reflection works particularly well for code generation, structured-output tasks, and any task where the cost of returning wrong information exceeds the cost of an extra inference call. The reflection pattern adds 30 to 100 percent inference cost but reduces error rates by 20 to 50 percent on hard tasks.
Hierarchical reasoning. For complex agents, a top-level reasoning layer decides which sub-agent or workflow to invoke; sub-agents handle specialized reasoning within their domain. Hierarchical reasoning is the pattern behind multi-agent systems and is covered at multi-agent system.
The deliverable for Step 4 is a working reasoning loop with logged decision traces. Teams that build reasoning without traces lose the ability to debug failures; traces are how the team identifies whether a wrong answer came from bad retrieval (Layer 1 problem), bad reasoning (Layer 2 problem), or a bad tool call (Layer 3 problem).
AI Agent Development Step 5: Build the Action Layer
Step 5 of AI agent development is the action layer. The agent invokes tools, calls APIs, queries databases, and (with permission) modifies state in connected systems. Three sub-systems make up the action layer.
Tool definitions and function calling. Every action the agent can take is defined as a tool with structured input parameters and a typed output. Modern model providers (OpenAI, Anthropic, Google) all support function calling natively. The agent receives a list of available tools, decides which to call, generates structured arguments, and the developer-side code executes the actual function. The trade-off in tool design: too few tools and the agent cannot accomplish the task; too many tools and the agent gets confused about which to use. The sweet spot is 5 to 15 tools per agent for most production use cases.
Model Context Protocol (MCP). Anthropic’s open standard for agent-tool integration, gaining rapid adoption in 2026. MCP separates tool definitions from agent implementations: tools live in MCP servers that any MCP-compatible agent can invoke. The result is a growing ecosystem of pre-built MCP servers for common integrations (Google Drive, Slack, GitHub, Notion, databases, browsers) that AI agent development teams can plug in rather than build from scratch. The specification lives at the Model Context Protocol specification.
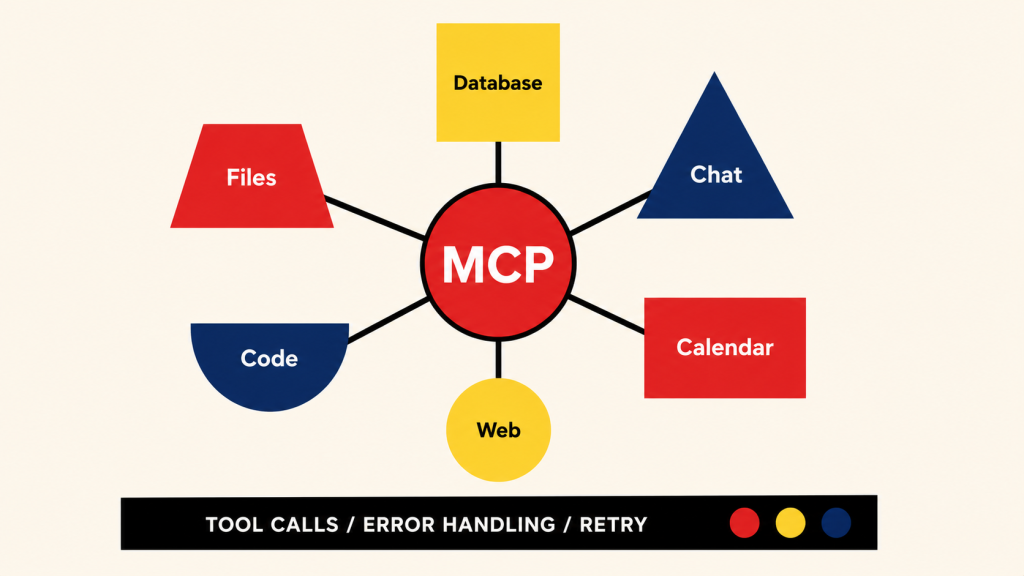
Error handling and partial-result handling. This is where most agent action layers fail in production. The tool times out: what does the agent do? The tool returns an error: does the agent retry, escalate, or fail gracefully? The tool succeeds partially (10 of 20 records returned): can the agent reason about the partial result? Production agents need explicit error-handling patterns for every tool, retry logic with exponential backoff, and graceful degradation when tools are unavailable. Skipping this work produces agents that fail silently on the first edge case.
The architectural pattern that works in production: every tool call is logged with input, output, latency, and error state. A separate error-handling tier intercepts failures and decides whether to retry, route to a different tool, or surface the error to the user. Teams that build the action layer without instrumentation cannot diagnose why their agent fails on day 8.
The action layer is where AI agent development teams most often discover they need more senior engineering capacity than they planned for. The patterns are not hard once you know them; they are hard to invent from scratch on a deadline.
AI Agent Development Step 6: Build the Memory Layer
Step 6 of AI agent development is the memory layer. Without memory, every interaction with the agent starts from scratch and the user experience is shallow. With memory, the agent retains context across sessions, learns user preferences, and produces compounding value over time.
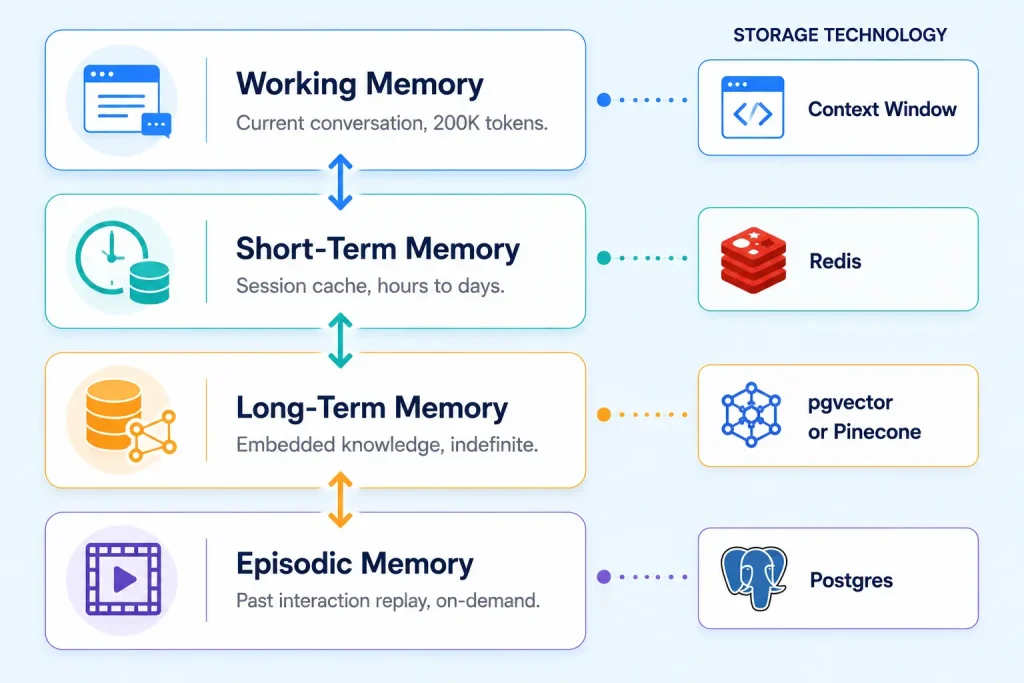
Four memory types make up the agent memory architecture:
Working memory. The current conversation context held in the LLM’s context window. Modern frontier models (Claude Sonnet, GPT-5) support 200K to 1M token context windows in 2026, but using the full window costs proportionally more per inference. The pattern in production: keep the working memory to the last 10 to 30 turns plus retrieved relevant context, not the entire conversation history.
Short-term memory. Session state cached in Redis or equivalent. Active user goals, intermediate computation results, recent tool outputs. Short-term memory survives across multiple agent invocations within a session but is typically cleared after hours or days of inactivity. The pattern: serialize agent state as JSON, key by session ID, set TTL of 24 to 72 hours.
Long-term memory. User preferences, learned patterns, and persistent knowledge stored in a vector database (pgvector, Pinecone, Weaviate). The agent retrieves relevant long-term memory at the start of each session by embedding the current context and querying for similar past memories. The pattern: write key facts (“user prefers email over Slack”, “user is working on Q3 sales pipeline”) to the vector store; retrieve top-k relevant memories at session start.
Episodic memory. Specific past interactions stored as structured records in Postgres. The agent can recall “what happened last Tuesday at 3pm when the user asked about pricing” with full fidelity, including the exact response and outcome. Episodic memory is heavy storage but light query; teams use it sparingly for high-stakes interactions where exact replay matters.
The architectural decisions in the memory layer: which information lives where (working vs short-term vs long-term vs episodic), how memory is written (automatic extraction vs explicit user signals), how memory is retrieved (semantic search vs structured query), and how memory is forgotten (TTL, summarization, explicit deletion). Each decision has implications for cost, latency, and user trust.
AI Agent Development Step 7: Build the Learning Layer
Step 7 of AI agent development is the learning layer. The agent improves over time through systematic evaluation, feedback capture, and iteration. Without the learning layer, the agent degrades as the underlying model API evolves and as user needs shift.
Evaluation harness. A curated set of 50 to 500 test cases that the team runs against the agent on every change. Each test case has an input (user request), an expected output (correct agent behavior), and a scoring function (exact match, semantic similarity, custom logic). The evaluation harness runs in CI/CD; failing tests block deploys. Teams that ship without evaluation discover regressions days or weeks after they deployed.
LLM-as-judge. For tasks where the correct answer is subjective or open-ended (drafting emails, generating reports), a second LLM evaluates the agent’s output against the expected behavior. LLM-as-judge correlates with human evaluation at 70 to 85 percent accuracy and runs in seconds vs the days human evaluation requires. The pattern is now standard in AI agent development workflows.
Production telemetry and feedback capture. Every agent interaction logs the input, the agent’s reasoning trace, the actions taken, the output, the latency, and the user’s response (accepted, edited, rejected, ignored). User corrections become training data for prompt tuning. User rejections trigger root-cause analysis: was it bad retrieval (Layer 1), bad reasoning (Layer 2), bad tool call (Layer 3), or bad memory (Layer 4)?
Prompt iteration. The system prompt that defines the agent’s behavior evolves over time based on failure data. The pattern: identify a failure mode from production telemetry, write a new evaluation case that captures it, modify the prompt to handle the case, run the evaluation harness to confirm no regressions, deploy. Iteration cycles run weekly in mature AI agent development teams.
Fine-tuning (where justified). When a specific task is high-volume and the cost of running a premium model exceeds the cost of fine-tuning a smaller model, fine-tuning becomes worth it. Fine-tuning a 7B-parameter open-source model on 1,000 to 10,000 task-specific examples produces specialized agents that match larger models at 1/10 the inference cost. The trade-off is operational complexity (managed fine-tuning APIs from Anthropic, OpenAI, Together AI reduce but do not eliminate this).
The deliverable for Step 7 is an evaluation suite that runs in CI, production telemetry that captures the data needed to identify failure modes, and a documented iteration cadence (weekly prompt review, monthly evaluation expansion). Teams that ship without the learning layer ship v1.0 and never reach v1.1.
The AI Agent Development Stack: Frameworks and Infrastructure
AI agent development assembles a stack of frameworks, model APIs, vector databases, hosting, and observability tools. The 2026 default stack:
Agent orchestration framework. LangGraph (LangChain ecosystem) is the dominant choice for graph-based agent workflows with explicit state management. AutoGen (Microsoft) leads on multi-agent collaboration patterns. CrewAI is the rising choice for role-based multi-agent systems with simpler APIs. For simple single-agent builds, no framework at all (direct API calls with custom orchestration) is often the right choice; frameworks add complexity that small agents do not need.
Model APIs. Anthropic (Claude), OpenAI (GPT-5), Google (Gemini), and the open-source providers (Together AI, Replicate, Hugging Face Inference) for self-hostable models. Most production AI agent development uses 2 to 3 providers routed by task, as covered in Step 2.
Vector databases. pgvector (Postgres extension) for tight integration with relational data and operational simplicity. Pinecone for managed scale and zero-ops. Weaviate for hybrid search (semantic + keyword) and self-hosting flexibility. Qdrant for performance-sensitive workloads. The choice depends on existing infrastructure (already on Postgres? use pgvector), expected scale (under 10M embeddings? pgvector handles it), and team capability.
Backend infrastructure. TypeScript + Node.js for full-stack TypeScript saas integration, Python for ML-heavy workloads. Hosting on Vercel for Next.js front-ends, AWS or Fly.io for backend agent workers. The broader saas tech stack patterns are at the 2026 saas tech stack.
Observability. LangSmith (LangChain) for trace-level agent debugging. Helicone for LLM cost tracking and caching. Sentry for application errors. PostHog for product analytics. The observability stack is non-optional for production AI agent development; debugging an agent without traces is roughly 5x slower than debugging with traces.
AI Agent Development Cost in 2026: Honest Numbers
AI agent development costs come from five components: engineering labor, LLM inference, vector storage and retrieval, infrastructure, and ongoing maintenance.
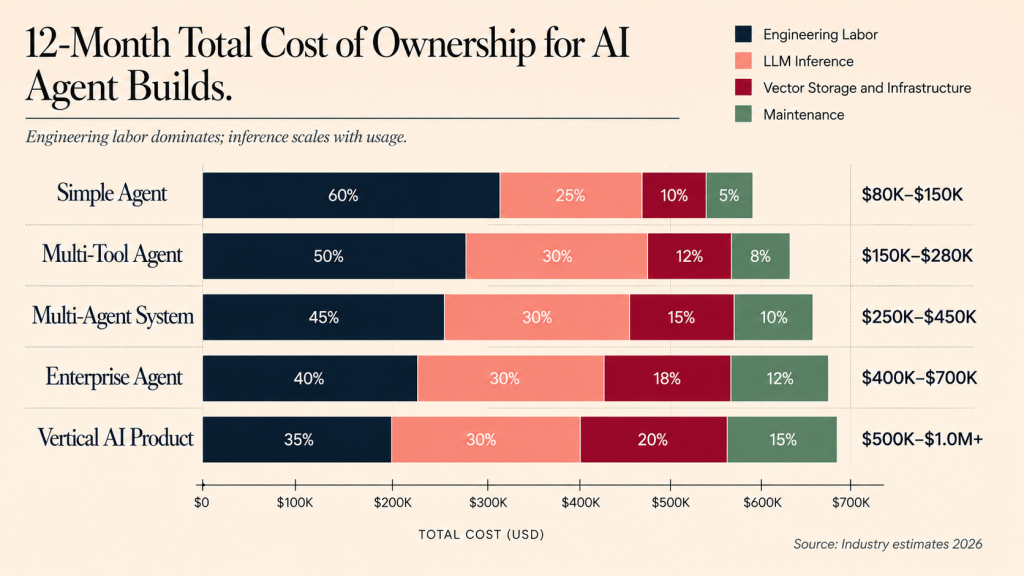
Engineering labor (the largest cost). A simple single-agent tool with tight scope: 4 to 8 weeks at $15K to $40K with a specialized agency. A multi-tool agent integrated into a saas product: 8 to 14 weeks at $40K to $100K. A multi-agent system with compliance requirements: 14 to 24 weeks at $100K to $300K. A vertical AI agent product (the agent IS the product): 16 to 32 weeks at $150K to $500K+.
LLM inference costs. Tokens per user per month depends on usage pattern. A B2B saas agent with moderate use (5 to 10 agent invocations per active user per day, each involving 2K to 8K tokens) costs $1 to $8 per user per month on premium models, $0.20 to $1.50 on cheap models. Heavy-AI products (document processing, agentic workflows, multi-step research) reach $10 to $50 per user per month. Pricing tiers need to absorb these costs; founders who priced before measuring inference cost have negative-margin paying customers.
Vector storage and retrieval. pgvector self-hosted: under $50 per month at MVP scale, scaling to $200 to $500 per month at 10M embeddings. Pinecone managed: $70 to $500 per month at typical agent scale. Embedding generation: $0.10 to $0.50 per 1M tokens depending on provider.
Infrastructure. Hosting (Vercel or AWS): $100 to $1,000 per month at MVP, scaling to $2K to $10K per month at growth stage. Background job processing for long-running agent tasks: $50 to $300 per month. Observability tools: $50 to $500 per month.
Maintenance. Ongoing prompt iteration, evaluation suite maintenance, model API migration when providers update, feedback loop tuning. Budget 10 to 20 percent of original build cost per year for steady-state maintenance.
The full breakdown by scenario with 5 worked examples is at AI agent development cost. The broader saas build cost framework that contextualizes these numbers is at saas development cost.
AI Agent Development Timeline: 8 to 16 Weeks Realistic
The AI agent development timeline ranges from 8 to 16 weeks for an MVP depending on scope, team, and stack choices.
8-week timeline (simple single-agent tool). Possible when the agent is single-purpose, the integration surface is small (1 to 3 tools), the data is already structured, and the team has prior AI agent build experience. Build phases: Weeks 1 to 2 (job-to-be-done, model selection, perception layer), Weeks 3 to 4 (reasoning and action layers), Weeks 5 to 6 (memory and learning layers), Weeks 7 to 8 (hardening, evaluation, launch).
12-week timeline (multi-tool agent in a saas product). The default for most production AI agent development. Adds time for: deeper integration with existing saas data and workflows, more sophisticated tool surface (5 to 10 tools), per-tenant memory isolation, more thorough evaluation coverage. Build phases: same four 3-week pairs but each phase carries more scope.
16-week timeline (multi-agent system or compliance-heavy). Required when the agent ships into regulated industries (healthcare, finance, government), uses multi-agent coordination, or has 10+ tools and complex error handling. Adds time for: compliance architecture, security review, more rigorous evaluation, multi-agent orchestration testing.
Common timeline traps: scope creep mid-build (the new feature the agent “should also do”), unscoped tool development (each new tool adds 3 to 7 days), missing evaluation work treated as v2 problem (it is a v1 problem), integration surprises with the host saas product (assume 50 percent more time than initially estimated). The timeline patterns mirror saas MVP timelines covered in detail at the saas mvp timeline.
Common AI Agent Development Mistakes That Slip Projects
Six recurring mistakes account for most slipped AI agent development projects. Each is predictable and preventable.
Mistake 1: Treating the agent as a feature, not a workflow. Features have buttons; agents have goals. Teams that scope the agent as “add an AI assistant button” produce passive chatbots; teams that scope as “automate this multi-step workflow end-to-end” produce real agents. The framing decides the outcome.
Mistake 2: Skipping evaluation work. Without an evaluation harness, the team has no way to know whether changes improved or degraded the agent. The first time a regression hits production, the team realizes they should have built evaluation in week 2, not week 12. Evaluation is not optional.
Mistake 3: Using a single model for every task. Premium models for everything wastes 5 to 10x the inference cost; cheap models for everything produces unreliable reasoning on complex tasks. Production AI agent development routes tasks to the right model tier.
Mistake 4: Underestimating the action layer. Tool integrations are not “just API calls”; they require error handling, retry logic, partial-result handling, permission checks, and observability. Teams that budget 1 week for tools spend 3 weeks.
Mistake 5: Missing per-tenant isolation. Multi-tenant saas agents need memory, evaluation data, and telemetry segregated by tenant. Retrofitting tenant isolation after launch costs 3 to 6 weeks and may require partial database migration. Build it in from day one. The multi-tenant patterns are at multi-tenant saas architecture.
Mistake 6: Ignoring agent security. Prompt injection, unauthorized tool use, data leakage through the agent, and adversarial inputs are real attack vectors in 2026. Production AI agent development requires explicit security controls covered at AI agent security.
AI Agent Development for SaaS Products
AI agent development for saas products is now the dominant build category in 2026. Most new saas builds include at least one AI agent surface; many treat the agent as the primary product surface.
The natural placement of AI agents in saas products:
In-product copilot. A persistent agent surface accessible from any screen, with context about what the user is doing. Drafts emails, summarizes data, explains features, runs workflows on the user’s behalf. Examples: Notion AI, Linear AI, Coda AI.
Onboarding agent. Personalized onboarding flow driven by an agent that asks the user about their use case and configures the product accordingly. Reduces time-to-value from days to minutes for complex products.
Customer support agent. Deflects support tickets through self-service, escalates complex cases to humans, and accelerates human agents with drafted responses. Covered at AI customer service agent and demonstrated by Helpnest in the Xgenious portfolio.
Background workflow agent. Asynchronous agents that run on schedules or triggers: nightly report generation, periodic data reconciliation, anomaly detection. The user does not interact with these agents directly; they consume the output.
Vertical specialist agent. An agent specialized for the saas’s specific vertical: a sales agent for sales saas, an HR agent for HR saas, a marketing agent for marketing saas. Vertical specialization commands premium pricing.
The deeper treatment of AI agent for saas patterns, ROI math, and integration architecture lives at AI agent for saas. For the broader build framework that places AI agent development in the saas decision space, see how to build a saas in 2026.
Agency vs In-House for AI Agent Development
The choice between hiring a specialized agency and building AI agents in-house follows the same general pattern as other engineering work, with AI-specific wrinkles.
Agency wins when: The team lacks senior AI engineering capacity; the build needs to ship in under 12 weeks; the saas has compliance requirements (HIPAA, SOC 2) that benefit from agency experience; the founder needs fixed-price predictability. Agencies in this space charge $40K to $300K per engagement depending on scope.
In-house wins when: AI is the core product (not a feature on top of a non-AI product); the company has post-PMF revenue to fund a permanent team; ongoing iteration is heavy; the AI capability is a defensible moat. In-house AI engineers in 2026 command $200K to $500K (US) for senior level; smaller markets and offshore engineers cost less.
Hybrid wins for most. Agency builds the initial AI agent, in-house team takes over for ongoing iteration starting at month 6 to 12. This pattern mirrors the broader hybrid that works for saas builds and is covered at saas development agency vs in-house.
For founders ready to engage a fixed-price agency for AI agent development with the patterns described in this guide, see our AI agent development services.
Conclusion: AI Agent Development in 2026 Is a Discipline, Not a Demo
AI agent development in 2026 has matured into a discipline with 7 critical steps (job-to-be-done, model selection, perception, reasoning, action, memory, learning) and a 5-layer Capability Stack that every production agent implements. Teams that follow the discipline ship working agents that produce real ROI; teams that skip the discipline ship demos that fall over in production.
The dominant pattern across successful AI agent development projects in 2026: tight scope on the job-to-be-done, multi-model routing for cost optimization, RAG-based perception for context grounding, structured reasoning with reflection, well-defined tool surfaces with error handling, multi-tier memory for retention, and evaluation harnesses that catch regressions. None of this is exotic; all of it is what separates working agents from broken ones.
AI Agent Development FAQ
1. How long does AI agent development take?
8 to 16 weeks for an MVP with a specialized agency and disciplined scope. 8 weeks for simple single-agent tools, 12 weeks for multi-tool agents integrated into a saas product, 16 weeks for compliance-heavy or multi-agent systems. Solo developers without prior AI agent experience need 16 to 28 weeks for equivalent scope. The realistic timeline depends on scope discipline and team experience more than on stack choices.
2. How much does AI agent development cost?
$15K to $300K for an MVP depending on scope. Simple agents at the low end, multi-agent systems at the high end. Ongoing costs include LLM inference ($1 to $50 per active user per month), vector storage ($50 to $500 per month at typical scale), and infrastructure ($100 to $2,000 per month). Maintenance costs 10 to 20 percent of original build per year. Full breakdown at AI agent development cost.
3. What is the right LLM provider for AI agent development?
The right answer is rarely one provider. Production agents typically use Anthropic (Claude) or OpenAI (GPT-5) for premium reasoning surfaces, a cheap model from the same provider for background tasks, and occasionally open-source models for data residency or fine-tuning. The routing pattern saves 40 to 70 percent on inference cost versus a single-provider strategy.
4. Do I need a framework like LangChain for AI agent development?
Not always. Simple single-agent builds with 1 to 3 tools often work better with direct API calls and custom orchestration. Frameworks (LangGraph, AutoGen, CrewAI) earn their complexity for multi-agent systems, complex state management, or teams that benefit from pre-built patterns. The right answer depends on agent complexity, not on framework popularity.
5. How do I handle prompt injection and AI agent security?
Prompt injection is the most common AI agent security risk in 2026. Defense includes input validation, structured output enforcement, tool-level permission checks, rate limiting per user, audit logging of all agent actions, and isolation of untrusted content (RAG-retrieved data, user-provided documents) from the agent’s instructions. Full coverage at AI agent security.
6. Can AI agents replace human employees?
Some narrow workflows yes, most workflows no. AI agents in 2026 are excellent at structured, well-defined tasks with clear success criteria (customer support deflection, document processing, code review assist, sales research). They are weak at workflows requiring judgment under uncertainty, relationship management, novel problem-solving, and political negotiation. The right framing is “agents augment humans on specific workflows” rather than “agents replace humans.”
7. What is the difference between AI agent development and chatbot development?
Chatbots answer messages reactively; AI agents pursue goals proactively. Chatbots are typically stateless or session-stateful; AI agents are stateful with persistent memory. Chatbots use a few well-defined intents; AI agents handle open-ended user goals and decide what actions to take. The same LLM can power both, but the engineering work to build an agent is meaningfully larger. Full comparison at AI agent vs chatbot.
